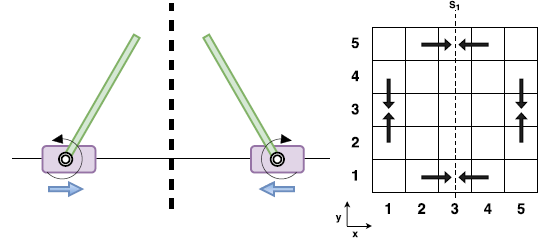
In this paper we explore methods to exploit symmetries for ensuring sample efficiency in reinforcement learning (RL), this problem deserves ever increasing attention with the recent advances in the use of deep networks for complex RL tasks which require large amount of training data. We introduce a novel method to detect symmetries using reward trails observed during episodic experience and prove its completeness. We also provide a framework to incorporate the discovered symmetries for functional approximation. Finally we show that the use of potential based reward shaping is especially effective for our symmetry exploitation mechanism. Experiments on various classical problems show that our method improves the learning performance significantly by utilizing symmetry information. Full paper available here.